Makine öğrenimi, kuruluşların verilerden değerli içgörüler elde etmesine yardımcı olarak sektörleri dönüştürmekte ve yeni inovasyonlara olanak sağlamaktadır. Makine öğrenimi alanında iki temel yaklaşım vardır: denetimli öğrenme ve denetimsiz öğrenme. Her ikisi de verilerdeki örüntüleri keşfetmeyi amaçlasa da, teknikleri açısından önemli ölçüde farklılık gösterirler. Denetimli ve Denetimsiz makine öğrenimi hakkında bazı kafa karışıklıklarına basit bir şekilde yanıt vermek istedim.
- Denetimli Öğrenme Nedir?
- Regresyon vs Sınıflandırma
- Denetimsiz Öğrenme Nedir?
- Kümeleme
- Boyutsallık Azaltma
- Denetimli ve Denetimsiz Makine Öğrenimi – Temel Farklılıklar
- Denetimli ve Denetimsiz Makine Öğrenimi Sık Sorulan Sorular
- Denetimli makine öğreniminin gerçek dünya uygulamaları nelerdir?
- Denetimli makine öğrenimi, regresyon ve sınıflandırma görevleri olarak nasıl kategorize edilir?
- Denetimsiz makine öğreniminin gerçek dünya uygulamaları nelerdir?
Bu blog yazısı, denetimli ve denetimsiz makine öğrenimi arasındaki farklara kapsamlı bir genel bakış sunarak farklı durumlar için hangi yaklaşımın en uygun olduğunu açıklamaya yardımcı olacaktır. Okuyucular, denetimli ve denetimsiz makine öğrenimini anlayarak sorunları çözmek ve hedeflerine ulaşmak için doğru teknikleri uygulayabilirler.
Denetimli Öğrenme Nedir?
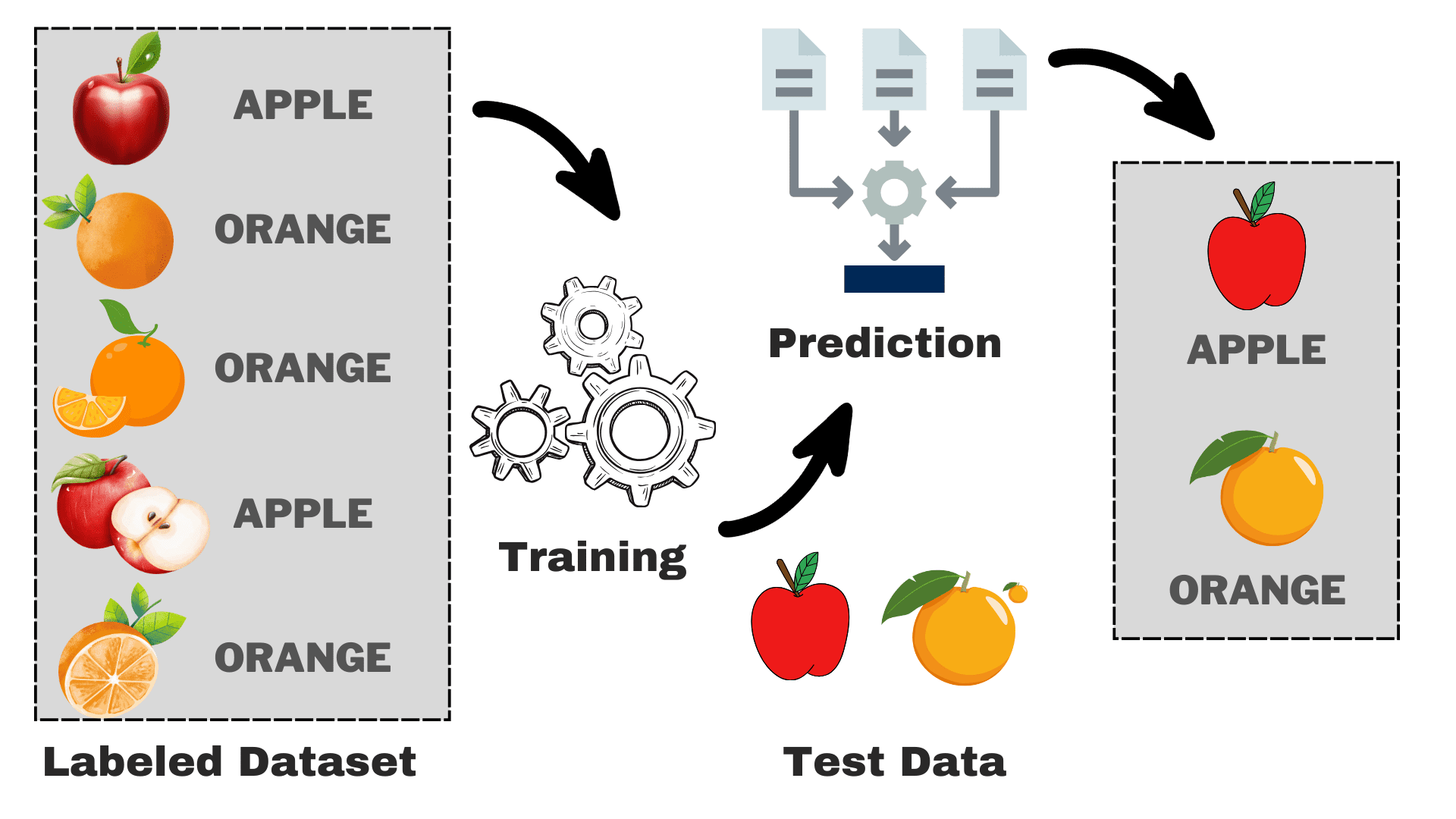
Denetimli öğrenme, makine öğrenimi modellerinin “doğru” yanıtların bilindiği etiketli veri kümeleri üzerinde eğitilmesini içerir. Denetimli öğrenmenin bazı önemli yönleri şunlardır:
- Önceden sınıflandırılmış veya kategorize edilmiş etiketli girdi verileri gerektirir. Etiketler, algoritmaların öğrenmesi için hedef çıktılar sağlar.
- Amaç, yeni, etiketlenmemiş örnekleri hedef etiketleriyle doğru bir şekilde eşleştirebilen bir model oluşturmaktır. Bu, denetimli modellerin tahminler veya sınıflandırmalar yapmasını sağlar.
- Yaygın denetimli öğrenme teknikleri regresyon ve sınıflandırma algoritmalarını içerir. Regresyon sürekli sayısal değerleri tahmin ederken, sınıflandırma örnekleri ayrık kategorilere atar.
- Gerçek dünya uygulamaları arasında spam filtreleme, kredi puanlama, tavsiye sistemleri ve tıbbi teşhis sistemleri yer almaktadır. Etiketlenmiş geçmiş veriler, daha sonra gelecekteki sonuçları tahmin eden denetimli modellere beslenir.
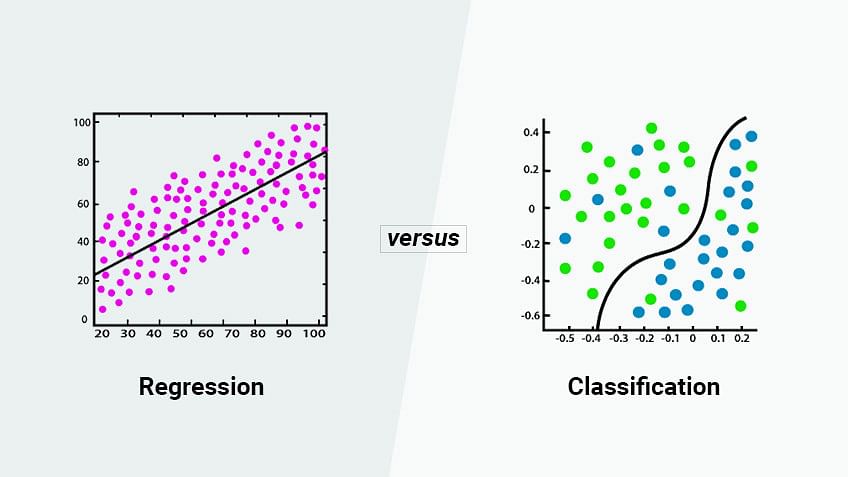
Regresyon vs Sınıflandırma
İki ana denetimli öğrenme problemi türü vardır:
- Regresyon – Konut fiyatları, hisse senedi fiyatları gibi sürekli hedef değişkenler için. Algoritmalar hedef değişkenleri bir aralık içinde tahmin etmeyi öğrenir.
- Sınıflandırma – Görüntü etiketleri, duygu analizi gibi kategorik hedef değişkenler için. Algoritmalar, hedef değişkenleri önceden tanımlanmış sınıflara veya gruplara atamayı öğrenir.
Denetimsiz Öğrenme Nedir?
Denetimsiz öğrenme, önceden tanımlanmış çözümler olmaksızın etiketlenmemiş veri kümeleriyle çalıştığı için denetimli öğrenmeden farklıdır. Bazı önemli hususlar şunlardır:
- Çıktılara atıfta bulunmadan girdi verileri üzerinde çalışır. Algoritmalar, verilerdeki gizli örüntüleri kendi başlarına bulmaya bırakılır.
- Amaç, etiketsiz verilerin altında yatan yapıyı ortaya çıkararak benzer örnekleri etiketler olmadan bir araya getirmek veya kümelemektir.
- Yaygın teknikler kümeleme, ilişkilendirme ve boyut azaltmadır. Kümeleme gizli örüntüleri tanımlarken ilişkilendirme değişkenler arasındaki ilişkileri bulur.
- Uygulamalar arasında pazar segmentasyonu, olay tespiti, genomik araştırma ve öneri sistemleri yer almaktadır. Daha sonra insanlar tarafından doğrulanabilecek içgörüleri keşfeder.

Kümeleme
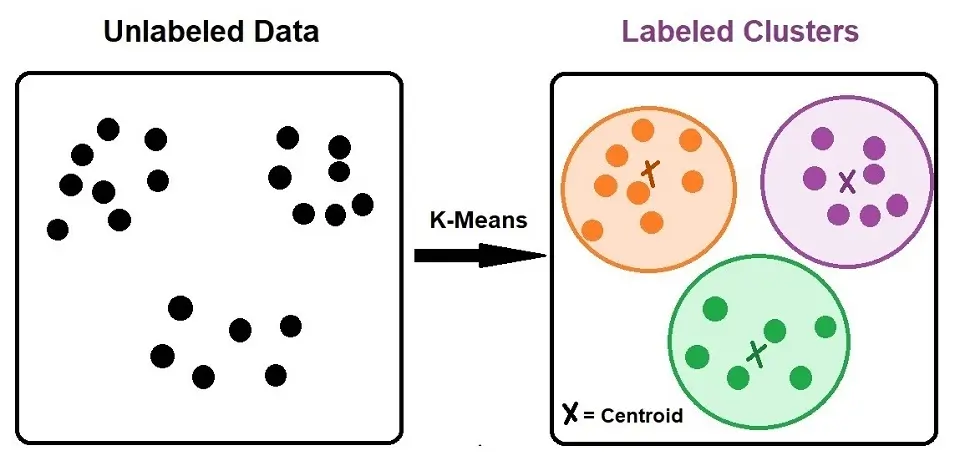
Kümeleme, etiketlenmemiş örnekleri benzerliklerine göre otomatik olarak gruplandıran önemli bir denetimsiz tekniktir. Popüler kümeleme algoritmaları şunları içerir:
- K-ortalamalar – Gözlemleri, her bir üyenin grubun centroidine veya merkezine en yakın olduğu K gruplarına böler.
- Hiyerarşik Kümeleme – Her bir bölünmenin en benzer kümeleri birleştirdiği ağaç tabanlı bir küme hiyerarşisi oluşturur.
- DBSCAN – Küme sayısını önceden belirtmeden rastgele şekillerdeki yoğunluk tabanlı kümeleri tanımlar.
Boyutsallık Azaltma
Bir diğer önemli denetimsiz teknik, eğilimleri ve kalıpları korurken yüksek boyutlu verileri daha az boyuta dönüştüren boyut indirgemedir. Örnekler şunları içerir:
- Temel Bileşen Analizi (PCA) – Verileri maksimum varyansı yakalayan ortogonal temel bileşenler üzerine yansıtır.
- T-Dağıtılmış Stokastik Komşu Gömme (t-SNE) – Veri noktaları arasındaki benzerlikleri ortak olasılıklara dönüştürerek yüksek boyutlu verilerin görselleştirilmesine yardımcı olur.
- Uniform Manifold Approximation and Projection (UMAP) – Doğrusal olmayan boyut azaltma için scanpy ve seaborn gibi popüler araçlara gömülüdür.
Denetimli ve Denetimsiz Makine Öğrenimi – Temel Farklılıklar
Denetimli ve denetimsiz makine öğrenimi arasındaki temel farklar şunlardır:
- Etiketli Veriler – Denetimli öğrenme, modelleri eğitmek için etiketli veri kümelerini kullanır, denetimsiz öğrenme ise önceden tanımlanmış etiketlere veya çözümlere sahip değildir.
- Hedefler – Denetimli, yeni veriler üzerinde doğru hedef etiketlerini tahmin etmeyi amaçlarken, denetimsiz etiketsiz verilerdeki gizli kalıpları keşfeder.
- Uygulamalar – Denetimli, tahmin ve sınıflandırma gibi problemler için uygundur. Denetimsiz; segmentasyon, anomali tespiti ve öneri sistemleri gibi görevler için parlar.
- Karmaşıklık – Denetimli algoritmalar daha basittir ancak kapsamlı etiketleme gerektirir. Denetimsiz, büyük etiketsiz veri kümelerini gizli içgörülerle ele alır.
- Değerlendirme – Denetimli modellerin doğruluğu test setleri üzerinde kesin olarak ölçülebilir. Denetimsiz sonuçlar, anlamlı örüntüleri tanımlamak için insan yargısına ihtiyaç duyar.
Özetle, hem denetimli hem de denetimsiz öğrenme, makine öğrenimi içinde değerli tekniklerdir. Doğru uygulama probleme, veri kümesi özelliklerine, analiz hedeflerine ve mevcut algoritmaların yeteneklerine bağlıdır. Denetimli ve denetimsiz makine öğrenimi arasındaki farkları anlamak, kuruluşların doğru yaklaşımı uygulamalarını ve verilerinden maksimum değer elde etmelerini sağlar. Sektörler arasında birçok gerçek dünya kullanım örneği ile makine öğrenimi, şirketlerin çalışma ve müşterilere hizmet verme biçiminde devrim yaratmaya devam ediyor.
Denetimli ve Denetimsiz Makine Öğrenimi Sık Sorulan Sorular
Denetimli makine öğreniminin gerçek dünya uygulamaları nelerdir?
- Spam Tespiti: Etiketli bir e-posta veri kümesi üzerinde denetimli öğrenme algoritması eğitilerek, gelen e-postaların spam veya gerçek e-posta olarak doğru bir şekilde sınıflandırılması sağlanabilir.
- Konuşma Tanıma: Denetimli öğrenme algoritmaları, ses klipleri ve bunların ilgili transkriptleri üzerinde eğitilerek, doğru konuşma tanıma sistemleri geliştirilebilir.
- Makine Çevirisi: Farklı dillerde eşleştirilmiş cümleler sağlanarak, denetimli öğrenme algoritmalarıyla bir dilden diğerine metin çevirisi yapılabilir.
Denetimli makine öğrenimi, regresyon ve sınıflandırma görevleri olarak nasıl kategorize edilir?
Denetimli makine öğrenimi, regresyon ve sınıflandırma olmak üzere iki temel görevlere ayrılabilir.
- Regresyon algoritmaları, çıktı olarak sürekli sayısal bir değeri tahmin etmeyi hedefler. Örneğin, boyut, konum ve oda sayısı gibi özelliklere dayanarak konut fiyatlarını tahmin etmek gibi.
- Sınıflandırma algoritmaları ise aksine, kesirli kategorileri veya sınıfları tahmin eder. Örnekler arasında bir resmin bir kedi mi yoksa bir köpek mi içerdiğini belirlemek veya bir tümörün iyi huylu mu yoksa kötü huylu mu olduğunu belirlemek yer alır.
Denetimsiz makine öğreniminin gerçek dünya uygulamaları nelerdir?
Denetimsiz makine öğrenimi çeşitli endüstrilerde geniş bir uygulama alanına sahiptir. İşte birkaç örnek:
- Müşteri Segmentasyonu: İşletmeler, müşterileri satın alma alışkanlıklarına, tercihlere veya demografik özelliklere göre gruplandırabilir. Bu sayede hedefe yönelik pazarlama stratejileri ve kişiselleştirilmiş öneriler sunabilirler.
- Anomalilerin Tespiti: Denetimsiz öğrenme, verilerdeki olağandışı desenleri veya aykırıları tespit ederek, sahtekarlık faaliyetlerini, ağ ihlallerini veya ekipman arızalarını tespit etmeye yardımcı olabilir.
- Görüntü ve Belge Kümeleme: Etiketlenmemiş görüntüler veya belgeler, benzerliklerine göre gruplandırılabilir. Bu, görüntü tanıma, belge düzenleme ve içerik önerileri gibi alanlarda yardımcı olur.









{kind=link}