
Algoritmaların hüküm sürdüğü makine öğrenimini dünyasında, özellik mühendisliğinin önemi küçümsenemez. Ham verileri anlamlı içgörülere dönüştürebilen ve modellerinizin gerçek potansiyelini ortaya çıkarabilen gizli bileşendir. Bu kapsamlı kılavuzda, özellik mühendisliğine şöyle bir bakacak, tanımını, tekniklerini ve yol gösterici örneğimiz olarak ünlü IRIS veri setini inceleyeceğiz. Makine Öğreniminde Feature Engineering yazımıza başlayalım!
- Feature Engineering (Özellik mühendisliği) Nedir?
- IRIS Veri Setini Anlamak
- Gerekli Kütüphaneler:
- Veri Setini Yükleyelim
- Feature Engineering Teknikleri
- 1. Ölçeklendirme ve Normalleştirme
- 2. Eksik Değerleri Ele Alma
- 3. Kategorik Değişkenlerin Kodlanması
- 4. Etkileşim Özellikleri Oluşturma
- 5. Özellik çıkarma
- 6. Özellik Seçimi
- ML Modelimizi Kuralım
- Verileri eğitim ve test setlerine ayıralım
- Bir makine öğrenimi modeli seçelim
- Modeli eğitelim
- Modeli değerlendirelim
- Tahminlerde bulunalım
- Sonuçları Değerlendirelim
Feature Engineering (Özellik mühendisliği) Nedir?
Makine öğrenimi alanında özellik mühendisliği, ham verileri model eğitimi için daha uygun bir biçime dönüştürme sanatıdır. Makine öğrenimi algoritmalarının performansını artırmak için özelliklerin seçilmesini, oluşturulmasını ve dönüştürülmesini içerir. Feature Engineering, ilgili bilgileri çıkararak ve gürültüyü ortadan kaldırarak modellerin tahmin gücünü artırır ve karmaşık kalıpları yakalamalarını sağlar.
IRIS Veri Setini Anlamak
Feature Engineering (Özellik Mühendisliği) kavramlarını açıklamak için, makine öğrenimi alanında ünlü bir kıyaslama veri kümesi olan IRIS veri kümesini seçtim. Veri kümesi, her biri üç özelliğe sahip 50 iris çiçeği örneğinden oluşmaktadır: sepal uzunluk, sepal genişlik, yaprak uzunluk ve yaprak genişlik. Amaç, çiçekleri üç türden birine sınıflandırmaktır: setosa, versicolor veya virginica.

Gerekli Kütüphaneler:
Şimdi kütüphanelerimizi ekleyerek incelemeye başlayalım!
- Sklearn.preprocessing from StandardScaler: Sayısal özelliklerin ölçeklendirilmesini ve normalleştirilmesini gerçekleştiren bir sınıf.
- Sklearn.preprocessing from OneHotEncoder: Kategorik değişkenlerin tek seferde kodlanmasını gerçekleştiren bir sınıf.
- Sklearn.impute from SimpleImputer: Veri kümesindeki eksik değerleri işleyen bir sınıf.
- Sklearn.decomposition from PCA: Özellik çıkarımı için temel bileşen analizini gerçekleştiren bir sınıf.
- Sklearn.feature_selectio from SelectKBest ve f_classif: İstatistiksel testlere dayalı olarak özellik seçimi gerçekleştiren sınıflar.
Veri Setini Yükleyelim



Veri Görselleştirme
Verisetinde eksik değer ya da ikileme bulunmadığı için görselleştirmelere geçiyoruz.


Sayısal özelliklerin dağılımlarını histogramları kullanarak görselleştirelim.

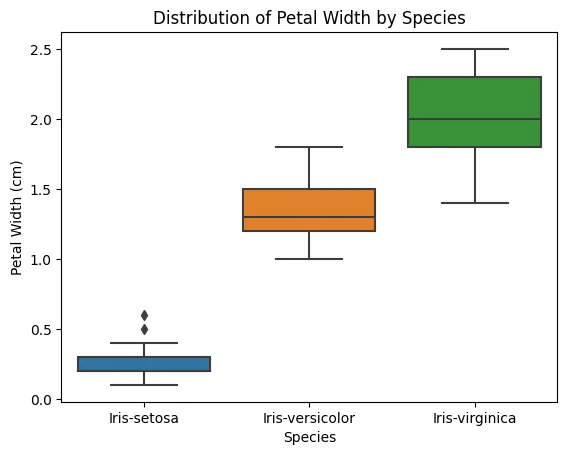
Her bir özelliğin farklı iris türleri arasındaki dağılımını ve değişkenliğini görmek için kutu grafikleri oluşturalım.
Feature Engineering Teknikleri
Bu bölümde, IRIS veri setini geliştirmek ve modellerimizin performansını artırmak için uygulanabilecek çeşitli özellik mühendisliği tekniklerini keşfedeceğiz. Her bir tekniği ayrıntılı olarak inceleyelim.
1. Ölçeklendirme ve Normalleştirme
Özellik mühendisliğindeki yaygın tekniklerden biri ölçeklendirme ve normalleştirmedir. Bu, özellikleri ortak bir ölçeğe dönüştürerek modele eşit katkıda bulunmalarını sağlamayı içerir. Bu teknik, özellikler farklı aralıklara veya ölçüm birimlerine sahip olduğunda özellikle kullanışlıdır.
SepalLengthCm, SepalWidthCm, PetalLengthCm ve PetalWidthCm sayısal özellikleri, scikit-learn’deki StandardScaler kullanılarak standartlaştırılmıştır. Bu, özelliklerin sıfır ortalama ve birim varyansa sahip olmasını sağlayarak onları karşılaştırılabilir ve belirli makine öğrenimi algoritmaları için uygun hale getirir.
2. Eksik Değerleri Ele Alma
SepalLengthCm, SepalWidthCm, PetalLengthCm ve PetalWidthCm sayısal özelliklerindeki eksik değerler (varsa), scikit-learn’den SimpleImputer tarafından sağlanan ortalama strateji kullanılarak hesaplanır. Bu, eksik değerleri ilgili her özelliğin ortalama değeriyle doldurur.
3. Kategorik Değişkenlerin Kodlanması
Kategorik değişken Türler, tek geçişli kodlama kullanılarak kodlanır. Scikit-learn’in OneHotEncoder’ı, kategorik değişkeni ikili sütunlara dönüştürmek için kullanılır; burada her sütun, orijinal Tür değişkenindeki benzersiz bir kategoriyi temsil eder.
4. Etkileşim Özellikleri Oluşturma
İki yeni özellik, SepalAreaCm2 ve PetalAreaCm2, sırasıyla SepalLengthCm ve SepalWidthCm ile PetalLengthCm ve PetalWidthCm’nin öğe bazında çarpımı gerçekleştirilerek oluşturulur. Bu etkileşim özellikleri mevcut iki özelliğin çarpımını yakalar ve modele ek bilgi sağlayabilir.
5. Özellik çıkarma
Veri setinin boyutluluğunu azaltmak için Temel Bileşen Analizi (PCA) uygulanır. Dört orijinal sayısal özellik SepalLengthCm, SepalWidthCm, PetalLengthCm ve PetalWidthCm, orijinal özelliklerin doğrusal kombinasyonları olan PCA1 ve PCA2 olmak üzere iki yeni özelliğe dönüştürülür. Bu yeni özellikler verilerdeki maksimum varyansın yönlerini temsil eder.
6. Özellik Seçimi
Bu kod satırı, özellik seçme tekniğini (SelectKBest) uyguladıktan sonra seçilen özellikleri depolamak için yeni bir DataFrame (selected_features_df) oluşturur.
ML Modelimizi Kuralım
Verileri eğitim ve test setlerine ayıralım
Modeli kurmadan önce verilerinizi bir eğitim seti ve bir test seti olarak bölmek çok önemlidir. Bu, modeli bir veri alt kümesi üzerinde eğitmemize ve görünmeyen veriler üzerindeki performansını değerlendirmemize olanak tanır. Bunu başarmak için sklearn.model_selection modülündeki train_test_split işlevini kullanalım.
Burada X_train ve y_train eğitim verileri (özellikler ve hedef), X_test ve y_test ise test verileri olacaktır.
Bir makine öğrenimi modeli seçelim
Bu örnek için Lojistik Regresyon modeliyle devam edelim;
Modeli eğitelim
Artık modeli eğitim verilerini kullanarak eğitebiliriz

Modeli değerlendirelim
Eğitimden sonra test verilerini kullanarak performansını değerlendirebiliriz.
Model accuracy: 1.0
Tahminlerde bulunalım
Modeli eğittikten sonra test verilerini kullanarak performansını değerlendirebiliriz.
Predicted labels: [0. 0. 1. 0. 0. 0. 0. 1. 0. 0. 1. 0. 0. 0. 0. 0. 1. 0. 0. 1. 0. 1. 0. 1.
1. 1. 1. 1. 0. 0.]
Modelin performansını daha ayrıntılı değerlendirmek için tahmin edilen etiketleri gerçek etiketlerle (y_test) karşılaştırabilirsiniz. Örneğin, sklearn.metrics modülündeki işlevleri kullanarak hassasiyet, geri çağırma ve F1 puanı gibi ölçümleri hesaplayabilirsiniz:
Classification Report:
precision recall f1-score support
0.0 1.00 1.00 1.00 19
1.0 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
Sonuçları Değerlendirelim
Örneğimizde, iris_data veri kümesinden en iyi 3 özelliği seçmek için puanlama fonksiyonu olarak karşılıklı bilgi ile SelectKBest özellik seçme tekniğini uyguladık. Bunu yaparak, veri kümesinin boyutluluğunu azalttık ve yalnızca en bilgilendirici özellikleri koruduk.
Feature Engineering uyguladıktan sonra, değiştirilmiş veri kümesi üzerinde bir Lojistik Regresyon modeli eğittik ve performansını değerlendirdik. Modelin test verilerinde 1,0’lık mükemmel bir doğruluk elde ettiğini gözlemledik; bu da seçilen özelliklerin son derece bilgilendirici olduğunu ve modelimizin örnekleri doğru bir şekilde sınıflandırmasını sağladığını gösteriyor.

Feature Engineering, özellikle de özellik seçimi, model performansının iyileştirilmesinde ve boyutluluğun azaltılmasında çok önemli bir rol oynar.
Puanlama fonksiyonu olarak karşılıklı bilgi ile kullanılan SelectKBest tekniği, hedef değişkenle olan ilişkilerine dayanarak en alakalı özellikleri seçmemizi sağlar.
Bu makalede, özellik mühendisliğinin (Feature Engineering) özünü ve makine öğrenimindeki rolünü araştırdık. Ölçekleme ve normalleştirme, eksik değerlerin ele alınması, kategorik değişkenlerin kodlanması, etkileşim özelliklerinin oluşturulması, özellik çıkarımı ve özellik seçimi gibi çeşitli teknikleri inceledik. Bu teknikleri ünlü IRIS veri setine uygulayarak, ham verilerin anlamlı içgörülere dönüştürülmesine tanık olduk.
Bu işlemler sayesinde yalnızca güçlü bir makine öğrenimi modeli oluşturmakla kalmadık, aynı zamanda model performansını iyileştirmede özellik mühendisliğinin önemini de öğrendik. Feature Engineering, en bilgilendirici özellikleri seçmemize olanak tanıyarak son derece doğru bir model ortaya çıkardı.
Feature Engineering yazısı için oluşturduğum Notebook’u Kaggle hesabımda bulabilirsiniz. Daha fazla veri bilimi içeriği için lütfen takipte kalın.










{kind=link}